Notes on Reinforcement Learning from Human Feedback
The purpose of this post is to document notes related to Reinforcement Learning from Human Feedback, an approach for updating a trained LLM to better match human preferences or values. The images and presentation follow the Generative AI with LLMs course by DeepLearning.AI on Coursera (see link in References).
- Aligning models with human values


- Q Learning is an alternative to PPO
- PPO updates weights of LLM based on human feedback in Reward Model (e.g. "helpful" or "not helpful")
- Agent can cheat the system via Reward Hacking (like empty stats in basketball)

- Can avoid Reward Hacking by comparing RL-updated LLM output vs Reference Model (frozen LLM) via KL Divergence. This gets added back via the Reward Model and PPO in what is essentially a control loop.

- KL Divergence is essentially a measure of the difference between 2 probability distributions. Here, it ensures that the reference policy and the updated policy do not differ by too much. In other words, it plays the role of a regularization term.
- Occurred to me that there are basically two levels to training:
1.) The foundational original training of a model (where the weights are initially random)
2.) Various additional levels of training (transfer learning, full fine-tuning, PEFT, RLHF)
- The various additional levels of training range from modifying all weights across the LLM to just a small subset using PEFT methods such as LoRA.
A nice cheat sheet describing the different levels of training:
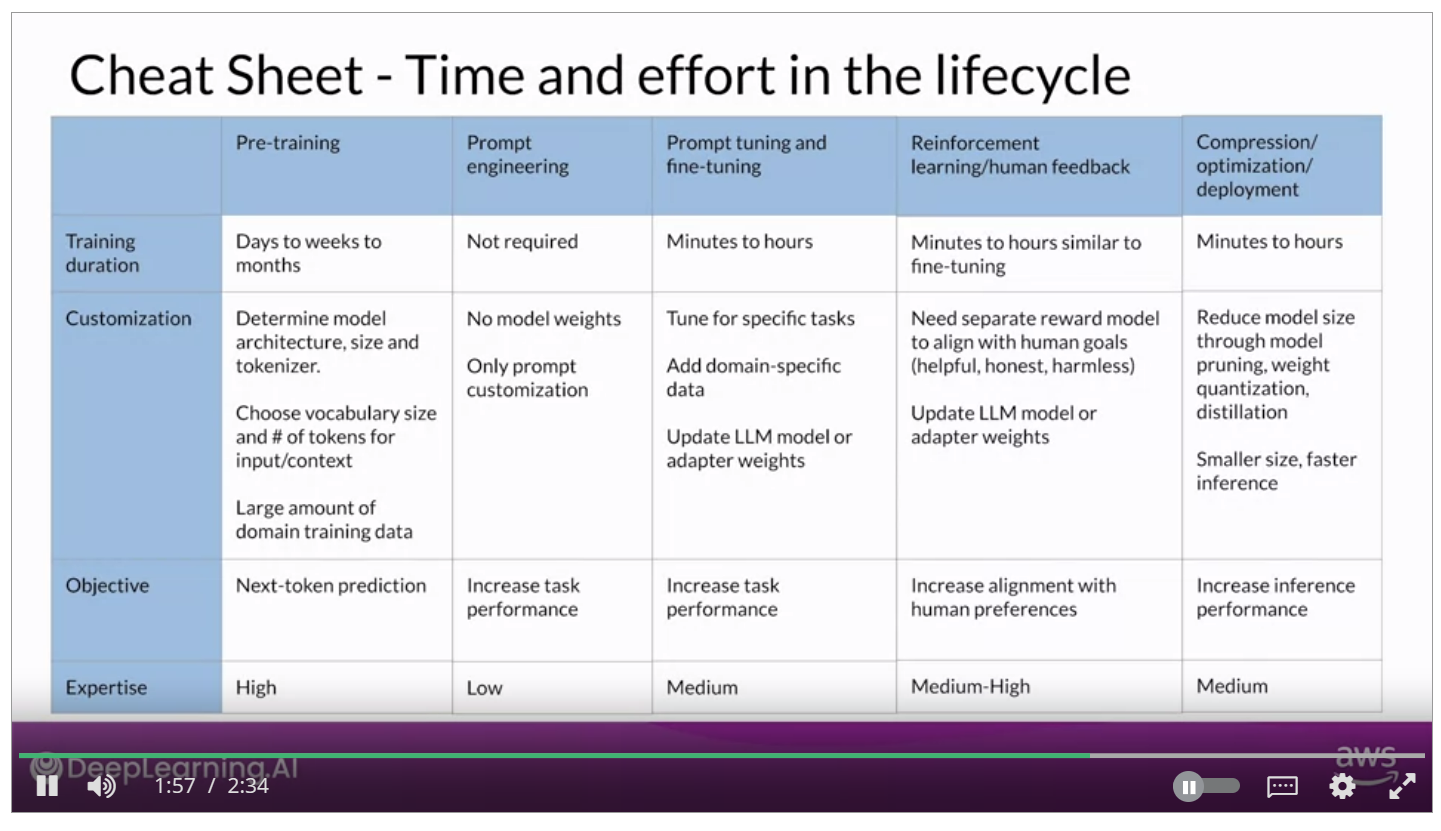


Comments
Post a Comment