Notes on Embedding Models: From Architecture to Implementation
I recently completed DeepLearning.AI's interesting short course on Embedding Models (Embedding Models: from Architecture to Implementation - DeepLearning.AI). In essence, the course covers how embeddings are used in ML to convert disparate forms of data e.g. text and images into numerical representations as vectors, with particular emphasis on linguistic text data. One idea I had from the course is that multimodal models may take advantage of embeddings since images and text can be converted into vector (or perhaps generalized matrix/tensor form) such that the resulting objects can undergo operations together in a compatible manner so as to enable multimodal generative AI e.g. producing images from text inputs. Presumably, this is how something like Gemini or ChatGPT produces images from user inputted text. It appears that OpenAI's early multimodal model CLIP (Contrastive Language-Image Pretraining) utilizes such an approach by mapping text and images into the same mathematical space. Vertex AI in Google Cloud looks to be using a similar approach as well quoting from the documentation: "the same semantic space with the same dimensionality. Consequently, these vectors can be used interchangeably for use cases like searching image by text or searching video by image."
Below are my rough notes from the course:
- Vector embeddings map real world entities to points in vector space.
- word2vec was the original fundamental model for mapping words to vectors
- Embeddings permit intuitive "semantic algebra" with intuitive interpretation as shown below where the vector algebra between the embeddings of "Yoda", "good" and "evil" produces "Vader".



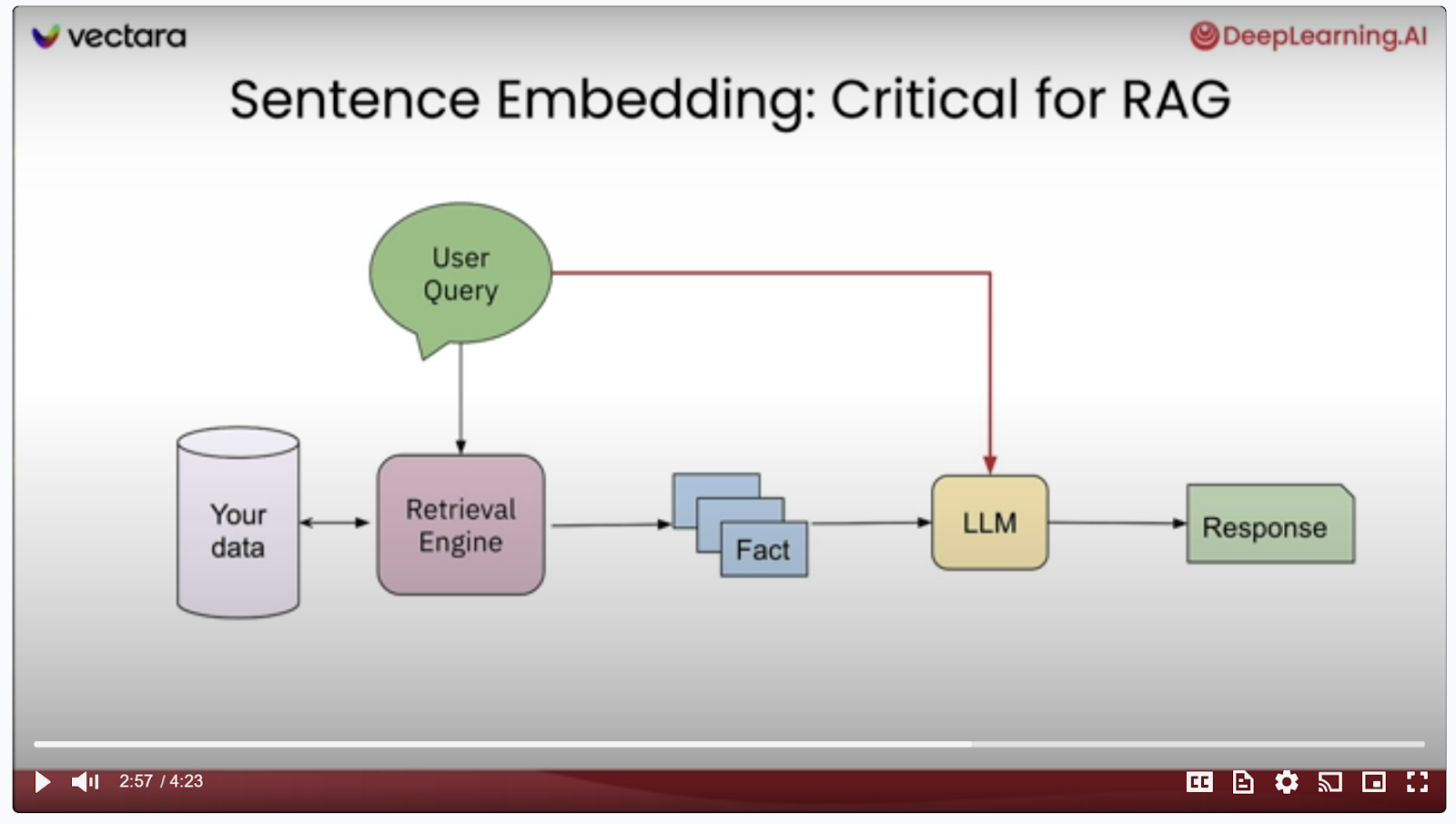











- Q: what is the difference between encoders and embeddings? Are encoders transformations that produce embeddings, or use embeddings or is the relationship different? The chain of logic appears to be tokenization -> encoding -> embedding. The below code sample shows succinctly that the spirit of the encoder is really to implement the conversion of the sentence into vector form. In this particular example, the embedding vectors are 768-dimensional. The embeddings appear to be implemented in a context-aware manner via the transformer encoder architecture (attention mechanisms in an autocorrelation manner). I think the right way to think about things is that encoders are a general notion for the initial layers of an LLM and they typically include transformations that produce embeddings.






References:

Comments
Post a Comment